Знакомство с датасетом
Посмотрим на данные в датасете, рисунок: Figure 1.
Code
import os
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
DATA_PATH = os.environ.get('KAGGLE_TREE_DATA', "data.csv")
df = pd.read_csv(DATA_PATH)
new_columns = ["_".join(c.split()) for c in df.columns]
df.columns = pd.Index(new_columns)
df.head()
Посмотрим более подробную информацию о датасете, рисунок: Figure 2.
Code
import io
buf = io.StringIO()
df.info(buf=buf)
lines = buf.getvalue().splitlines()[3:-2]
lines = lines[:1] + lines[2:]
line_list = [line.split()[1:3] + line.split()[4:5] for line in lines]
pd.DataFrame(data=line_list[1:], columns=line_list[0])
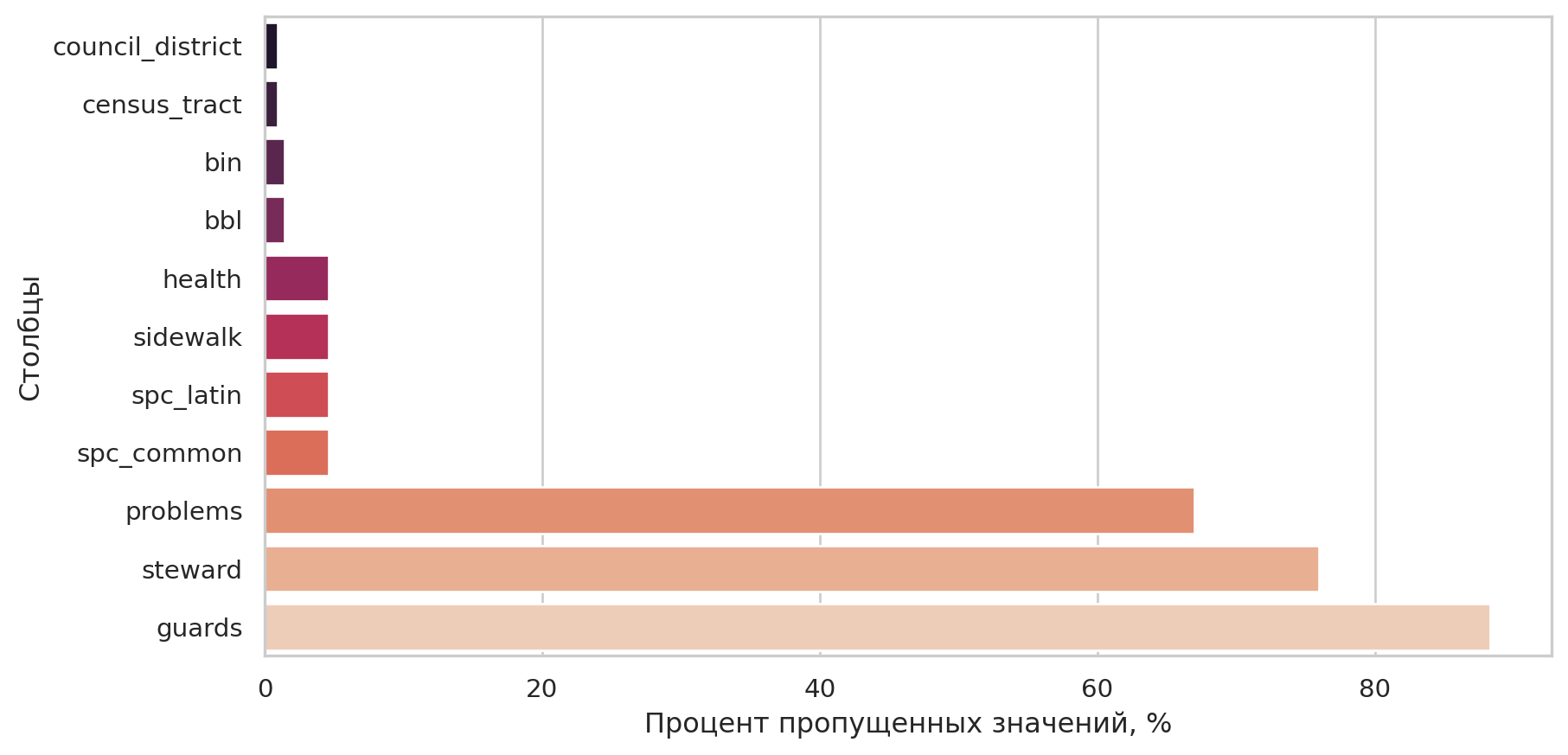
Посмотрим по каким столбцам есть пропущенные значения, рисунок: Figure 3.
Code
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid")
nullable_df = df.isna().sum()
missing_data_percentage_df = nullable_df[nullable_df > 0] / len(df) * 100
missing_data_percentage_df = missing_data_percentage_df.sort_values()
_, ax = plt.subplots(1, 1, figsize=(10, 5), sharex=True)
x = missing_data_percentage_df.values
y = missing_data_percentage_df.index
sns.barplot(x=x, y=y, hue=y, palette="rocket", ax=ax, orient="y")
ax.set_ylabel("Столбцы")
ax.set_xlabel("Процент пропущенных значений, %")
plt.show()
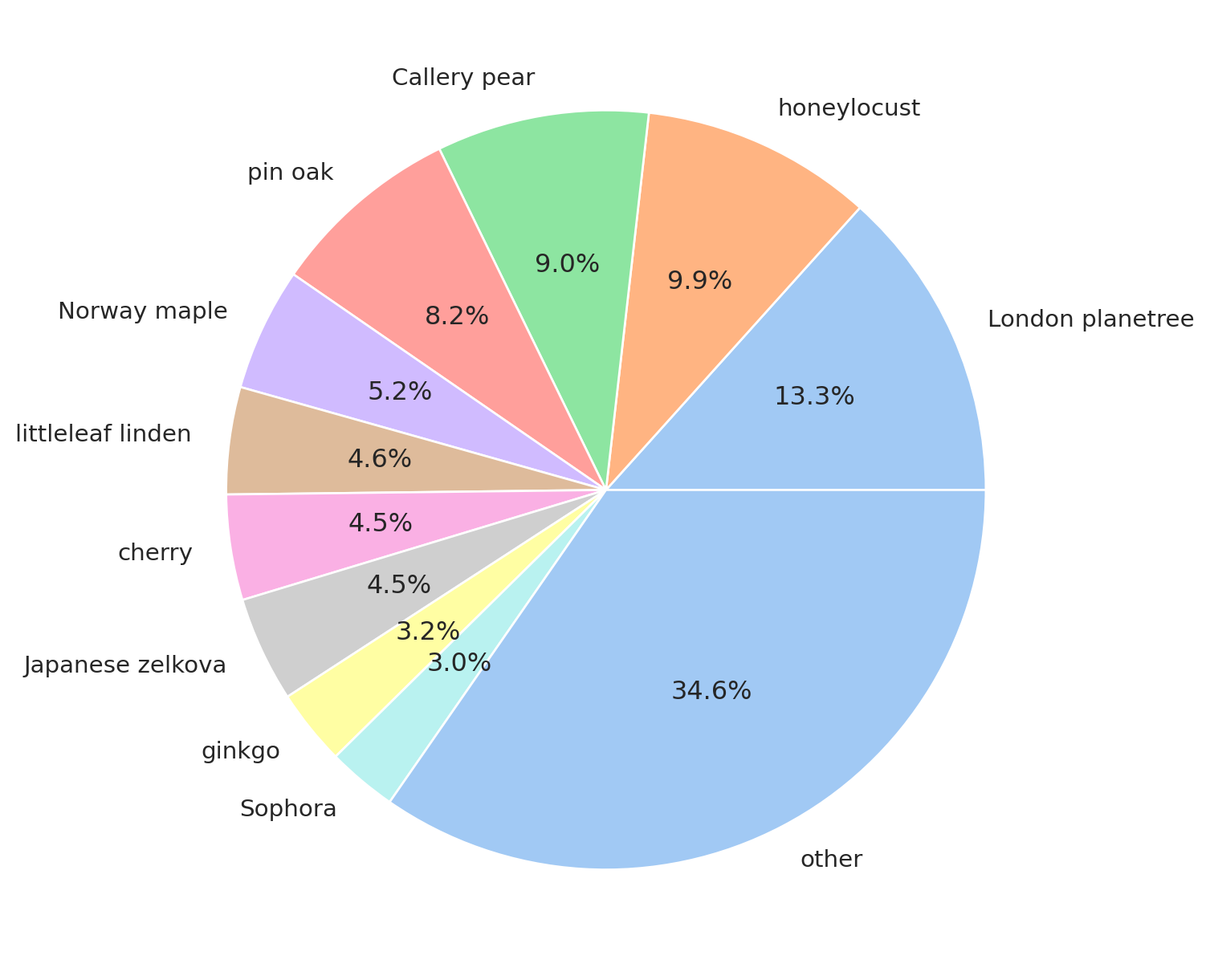
Посмотрим на виды деревьев, рисунок: Figure 4.
Code
N_SPECIES = 10
tree_species = df["spc_common"].value_counts()[:N_SPECIES]
labels = list(tree_species.index) + ["other"]
other_value = sum(v for v in df["spc_common"].value_counts()[N_SPECIES:].values)
values = list(tree_species.values) + [other_value]
colors = sns.color_palette('pastel')
_, ax = plt.subplots(1, 1, figsize=(12, 8), sharex=True)
ax.pie(values, labels=labels, colors=colors, autopct='%.1f%%')
plt.show()
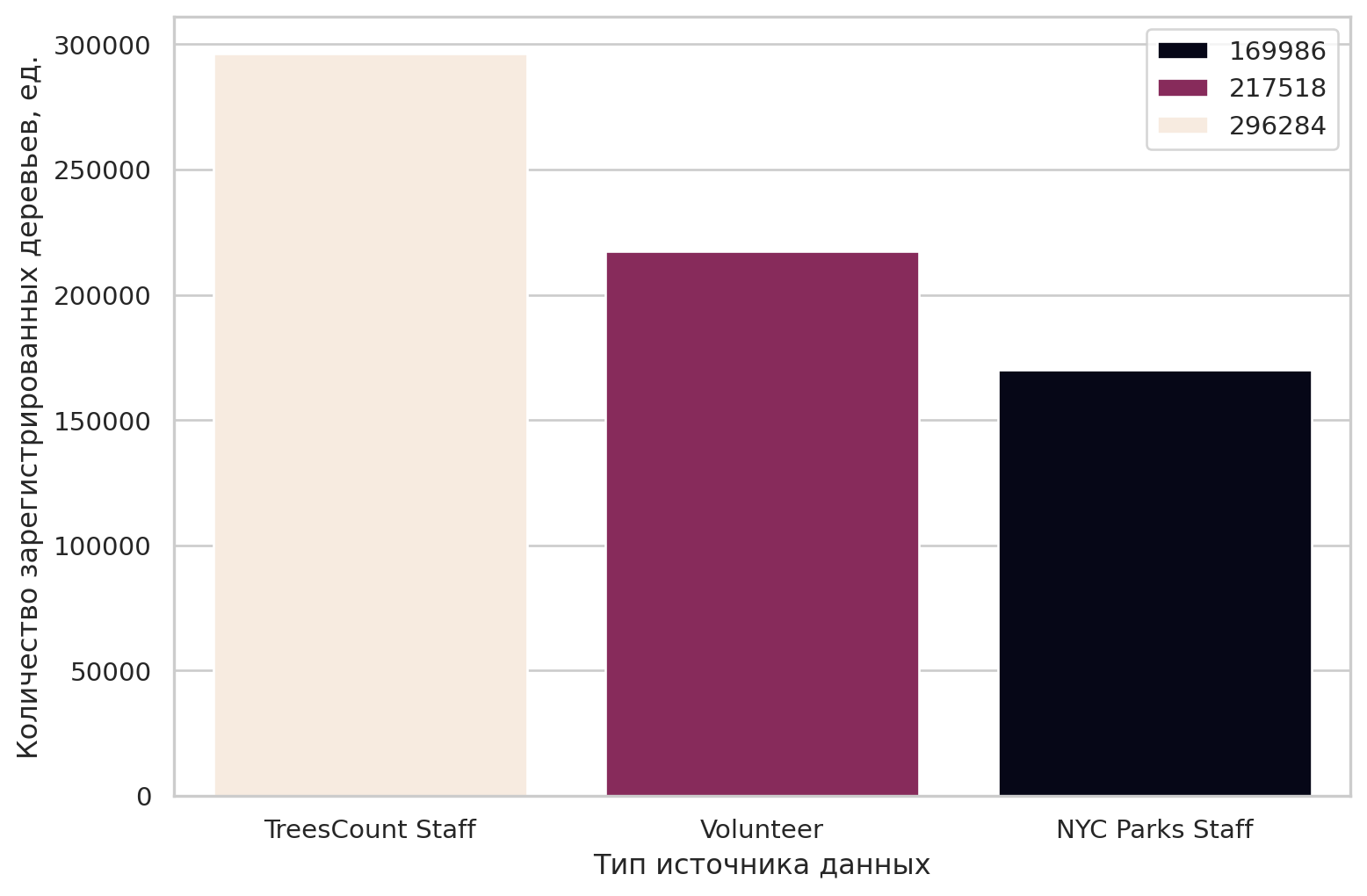
Посмотрим на распределение источников данных, рисунок: Figure 5.
Code
_, ax = plt.subplots(1, 1, figsize=(9, 6), sharex=True)
data_sources = df["user_type"].value_counts()
x1 = data_sources.index
y1 = data_sources.values
sns.barplot(x=x1, y=y1, palette="rocket", hue=y1, ax=ax)
ax.set_ylabel("Количество зарегистрированных деревьев, ед.")
ax.set_xlabel("Тип источника данных")
plt.show()
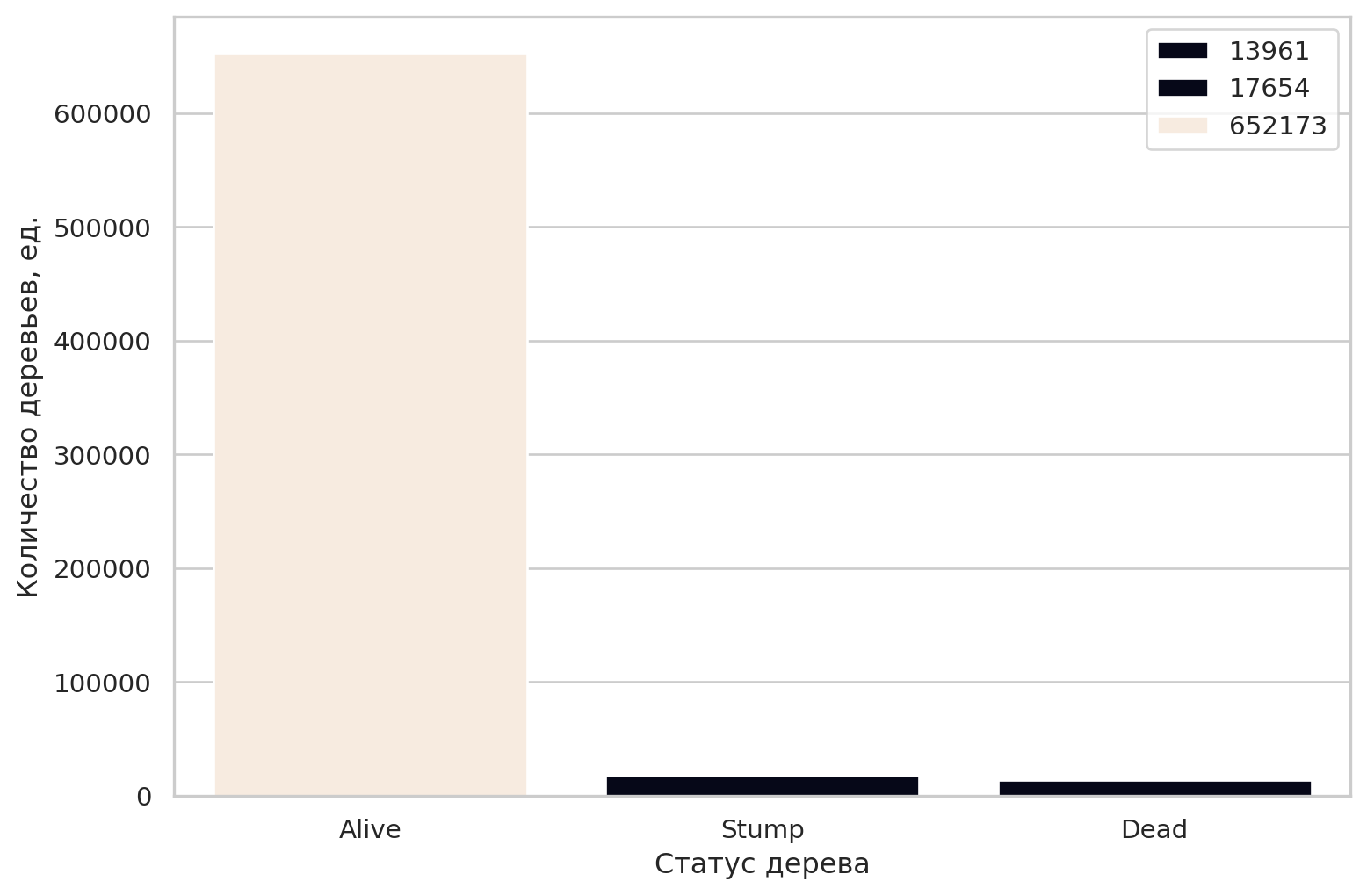
Посмотрим на распределение статуса деревьев, рисунок: Figure 6.
Code
_, ax = plt.subplots(1, 1, figsize=(9, 6), sharex=True)
statuses = df["status"].value_counts()
x2 = statuses.index
y2 = statuses.values
sns.barplot(x=x2, y=y2, palette="rocket", hue=y2, ax=ax)
ax.set_ylabel("Количество деревьев, ед.")
ax.set_xlabel("Статус дерева")
plt.show()
Анализ признаков
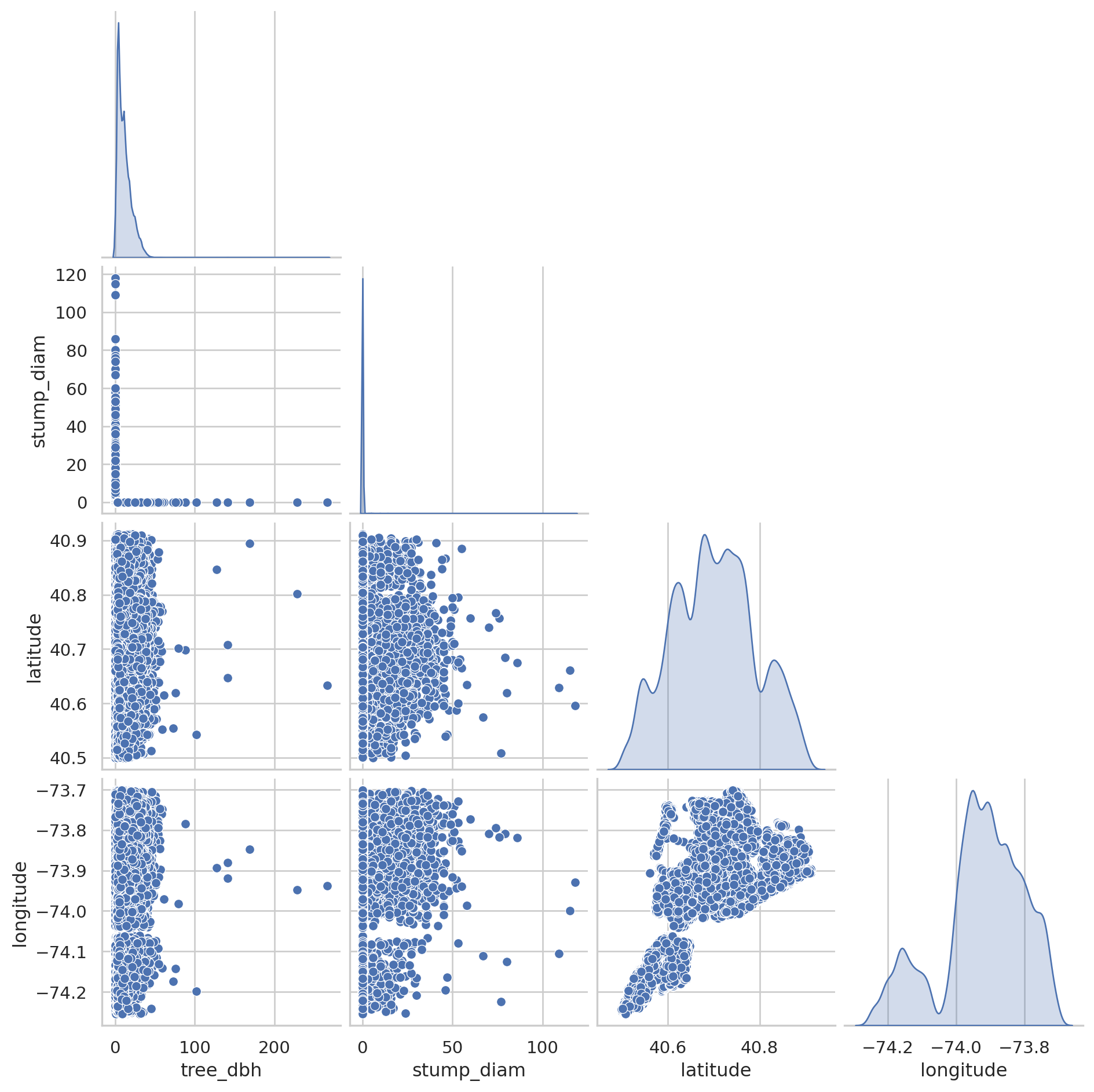
Проведем попарное сравнение некоторых признаков, рисунок: Figure 7.
Code
PAIRPLOT_FEATURES = ["tree_dbh", "stump_diam", "latitude", "longitude"]
PAIRPLOT_N_ROWS = int(len(df) * 0.1)
pairplot_df = df[PAIRPLOT_FEATURES].sample(PAIRPLOT_N_ROWS)
pairplot = sns.pairplot(pairplot_df, diag_kind="kde", corner=True)
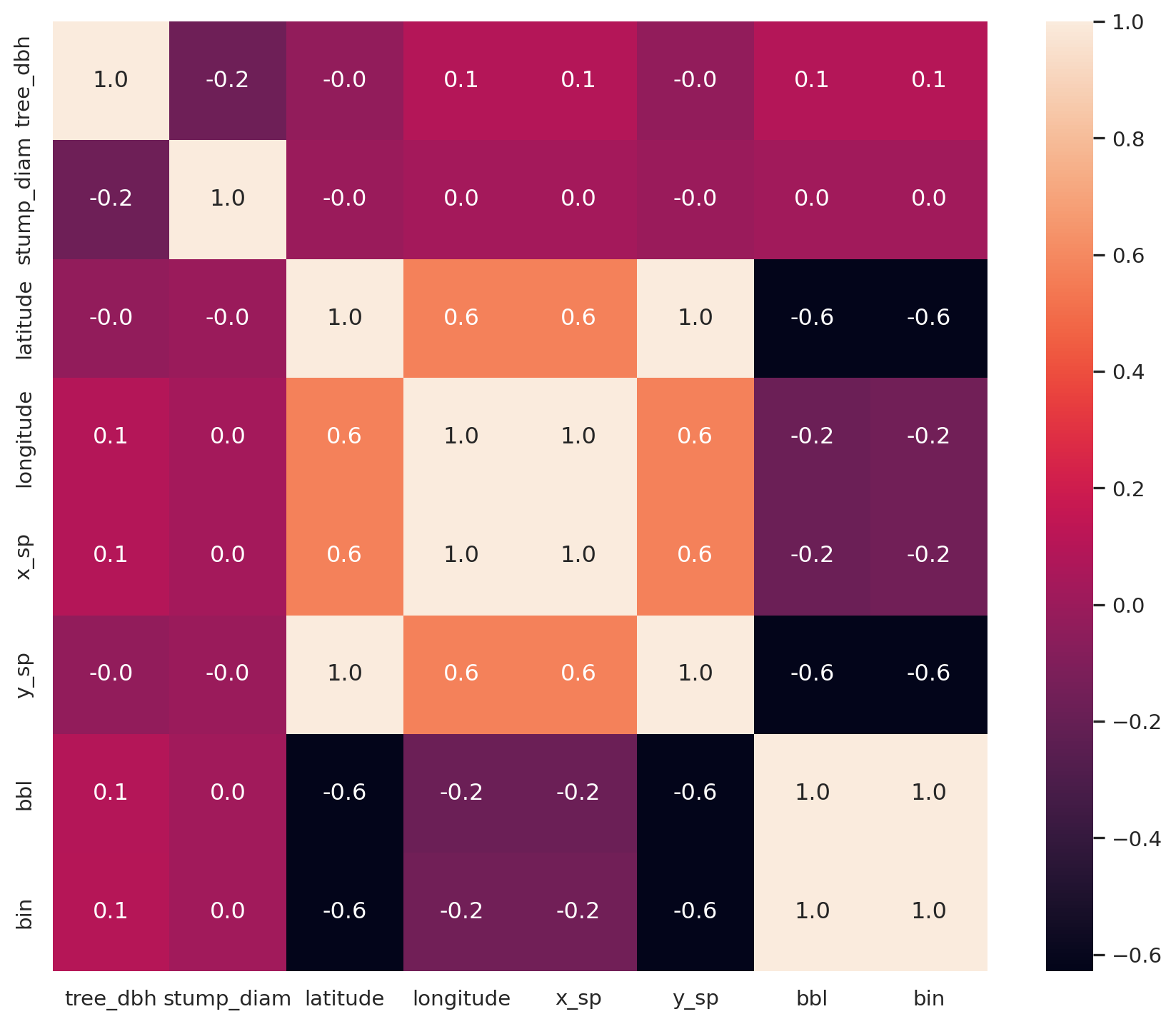
Посмотрим на тепловую карту корреляций вещественных признаков, рисунок: Figure 8.
Code
FLOAT_FEATURES = ["tree_dbh", "stump_diam", "latitude", "longitude", "x_sp", "y_sp", "bbl", "bin"]
corr_df = df[FLOAT_FEATURES].corr()
_, ax = plt.subplots(figsize=(11, 9))
sns.heatmap(corr_df, annot=True, fmt=".1f", ax=ax)
plt.show()
Визуализация на карте
Посмотрим небольшую выборку деревьев на карте, рисунок: Figure 9.
Code
import folium # type: ignore[import-untyped]
import numpy as np
from folium.plugins import GroupedLayerControl # type: ignore[import-untyped]
MAP_N_ROWS = 500
def colorize_by_health(health_status: str) -> str:
"""Get color by health status.
:param health_status:
:return: color
"""
color_dict = {
"Fair": "green",
"Good": "orange",
"Poor": "red"
}
unknown_color = "gray"
return color_dict.get(health_status, unknown_color)
center = df["latitude"].mean(), df["longitude"].mean()
map = folium.Map(location=center, zoom_start = 10)
species_groups = dict()
for spec in tree_species.index:
species_groups[spec] = folium.FeatureGroup(name=spec.lower())
other_group = folium.FeatureGroup(name='other')
indexes = np.random.choice(len(df), MAP_N_ROWS)
for idx in indexes:
row = df.iloc[idx]
popup = (
f"tree_id={row.tree_id} "
f"<br/> health={'Unknown' if pd.isna(row.health) else row.health} "
f"<br/> status={row.status}"
)
location = [row.latitude, row.longitude]
icon = folium.Icon(color = colorize_by_health(row.health))
group = species_groups.get(row.spc_common, other_group)
folium.Marker(location = location, popup = popup, icon = icon, fill_opacity = 0.9).add_to(group)
groups = list(species_groups.values()) + [other_group]
for group in groups:
map.add_child(group)
GroupedLayerControl(
groups={'Виды деревьев': groups},
exclusive_groups=False,
collapsed=False,
).add_to(map)
map
Выводы
- y_sp это преобразованный latitude
- x_sp это преобразованный longitude
- большинство деревьев живы